

Integridade de Entidade: Primary Key e Unique Key
Constraints Primary Key (PK) e Unique Key (UK) são utilizadas para identificar unicamente uma linha em uma tabela. Tanto PK’s quanto UK’s podem envolver mais de uma coluna. Desta forma, quando uma chave-primária é, por exemplo, constituída por mais de uma coluna é dito que a chave-primária é composta. O mesmo se aplica às UK’s. Mas quais são as diferenças entre primary key e unique key? Primary Key:
- Uma coluna que é envolvida em uma PK não pode ser nula;
- Só é possível existir uma chave-primária por tabela.
Unique Key:
- Uma coluna que é envolvida em uma UK pode ser nula;
- É possível existirem várias UK’s numa mesma tabela.
Primary Key
Mesma estando fora do escopo deste post, bem como da pauta de conteúdos do exame 70-461, vale à pena mencionar os acalorados debates na comunidade acerca da melhor escolha de colunas para a formação de uma PK. Há quem defende o uso de Natural Key, que é a estratégia de utilizar uma ou mais colunas existentes na tabela. Outros defendem a adoção de Surrogate Key, que é a estratégia de utilizar um valor que não é natural ao dado, como, por exemplo, a geração automática de um número ou código. Deixo este tema, Natural Key versus Surrogate Key, como uma dica de pesquisa para você, amigo leitor. Vejamos agora como criar chaves-primárias utilizando o bom e velho T-SQL.
use DBExame70461 go -- Criando diretamente na coluna CREATE TABLE dbo.Pessoa ( ID INT NOT NULL PRIMARY KEY, Nome varchar(50) NOT NULL);
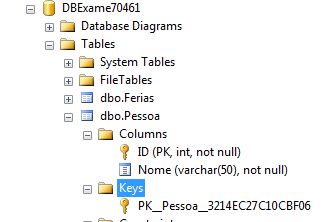
Note que o nome da constraint foi gerado automaticamente pelo SQL Server. Particularmente prefiro explicitar um nome para a constraint, conforme a seguir. — Atribuindo nome customizado à constraint
CREATE TABLE dbo.Pessoa ( ID INT NOT NULL CONSTRAINT PK_Pessoa PRIMARY KEY, Nome varchar(50) NOT NULL);
Atente para o fato de que a coluna ID não pode aceitar NULL. Mas o que acontecerá se eu declarar uma constraint primary key, omitindo a questão da nulidade? — Criando sem explicitar a nulidade da coluna
CREATE TABLE dbo.Pessoa ( ID INT CONSTRAINT PK_Pessoa PRIMARY KEY, Nome varchar(50) NOT NULL);
Conforme já mencionamos em artigo anterior, quando não explicitamos se uma coluna é NULL ou NOT NULL, o SQL Server, por padrão, definirá como NULL. Contudo, se estivermos criando uma PK na coluna então o SQL Server irá, automaticamente, definir a coluna como NOT NULL. Lembre-se: uma coluna envolvida numa PK não pode ser nulável. Uma outra alternativa para a criação de uma primary key é escrever conforme a seguir:
-- Criando uma PK no final da instrução CREATE TABLE dbo.Pessoa ( ID INT NOT NULL, Nome varchar(50) NOT NULL, CONSTRAINT PK_Pessoa PRIMARY KEY (ID) );
A grande vantagem da utilização desta alternativa é a possibilidade da criação de PK’s compostas de várias colunas. Veja:
CREATE TABLE dbo.Orcamentos ( Data DATE, Cliente_Id INT, Valor DECIMAL(15,2) NOT NULL, Obs VARCHAR(500) NULL, CONSTRAINT PK_Orcamentos PRIMARY KEY (Data, Cliente_Id) );
Unique Key
Esta é uma constraint às vezes desprezada pelos projetistas de bancos. Por exemplo, o valor da coluna “LOGIN” da tabela “USUARIOS” deve ser exclusivo (sem duplicidade), pois, não é permitido existir usuários com logins idênticos. Para satisfazermos essa regra bastará a criação de uma UNIQUE KEY na coluna LOGIN. Vejamos um exemplo:
CREATE TABLE dbo.Material ( ID INT NOT NULL CONSTRAINT PK_Material PRIMARY KEY, Nome VARCHAR(50) NOT NULL, NumeroDoFabricante INT NULL CONSTRAINT UK_Material_Numero UNIQUE, );
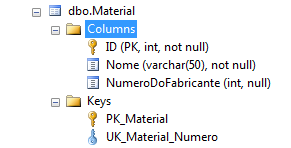
Perceba que a coluna “NumeroDoFabricante” é nulável. Conforme já comentado, isso é permitido, mas com a seguinte limitação: a quantidade de nulos não pode ser maior que 1. Vamos nos divertir explorando um exemplo.
-- Insere um registro com número do fabricante INSERT dbo.Material (ID, Nome, NumeroDoFabricante) VALUES (1, 'Mesa 4x4', 100); -- Insere um registro setando NULL no número do fabricante INSERT dbo.Material (ID, Nome, NumeroDoFabricante) VALUES (2, 'Mesa 5x6', NULL);
Até aqui temos as seguintes linhas na tabela:
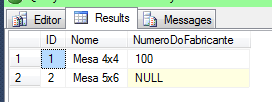
O que acontecerá se tentarmos inserir mais um registro contendo NULL na coluna “NumeroDoFabricante”?
-- Tentando inserir mais um registro com NULL no nº fabricante INSERT dbo.Material (ID, Nome, NumeroDoFabricante) VALUES (3, 'Janela 2x2', NULL); Msg 2627, Level 14, State 1, Line 2 Violation of UNIQUE KEY constraint 'UK_Material_Numero'. Cannot insert duplicate key in object 'dbo.Material'. The duplicate key value is (<NULL>).
A lógica é simples: já existe um nulo na coluna e, portanto, um novo nulo representa duplicação.
Integridade Referencial: Foreign Key
Uma constraint Foreign Key é usada para estabelecer uma ligação entre dados em tabelas, forçando um relacionamento consistente. Por exemplo, você pode querer se certificar de que existe um cliente antes de permitir que um pedido de vendas seja lançado para o cliente. Uma Foreign Key, criada na tabela A, deve referenciar uma Primary Key ou uma Unique Key existente na tabela B. Além disso, uma foreign key pode ser criada referenciando uma PK ou UK da mesma tabela, produzindo, assim, um auto relacionamento. É o caso do exemplo clássico da tabela EMPREGADO: um empregado é gerenciado por outro empregado, o qual tem papel de gerente.
CREATE TABLE dbo.Clientes ( Id int not null primary key, Nome varchar(50) not null ); INSERT dbo.Clientes VALUES (1, 'José'), (2,'Maria'); CREATE TABLE dbo.Pedidos ( Id int not null primary key, Cliente_Id INT NOT NULL CONSTRAINT FK_Pedidos_x_Cliente FOREIGN KEY REFERENCES dbo.Clientes(Id), Data datetime2 not null, Valor decimal(15,2) not null, ); INSERT dbo.Pedidos VALUES (1, 1, GETDATE(), 122.45);
O exemplo cria as tabelas CLIENTES e PEDIDOS, bem como uma foreign key na tabela PEDIDOS. Veja que explicitei um nome para a FK (FK_Pedidos_x_Clientes), o que é uma boa prática, vez que facilita uma futura leitura e interpretação do modelo. Uma alternativa para a criação de uma foreign key é fazer conforme a seguir:
CREATE TABLE dbo.Pedidos ( Id int not null primary key, Cliente_Id INT NOT NULL, Data datetime2 not null, Valor decimal(15,2) not null, CONSTRAINT FK_Pedidos_x_Cliente FOREIGN KEY (Cliente_Id) REFERENCES dbo.Clientes(Id) );
Mas o que acontecerá se tentarmos inserir um PEDIDO utilizando um ID inválido de cliente?
Declare @Cliente_Id INT = 3; INSERT dbo.Pedidos (Id, Cliente_Id, Data, Valor) VALUES (2, @Cliente_Id, GETDATE(), 122.45); Msg 547, Level 16, State 0, Line 2 The INSERT statement conflicted with the FOREIGN KEY constraint "FK_Pedidos_x_Cliente". The conflict occurred in database "DBExame70461", table "dbo.Clientes", column 'Id'.
Uma FK inclui uma opção chamada CASCADE, a qual permite que qualquer mudança de valor na PK ou UK da tabela referenciada, seja propagada, de forma automática, nas FK’s. Quando não explicitamos a opção CASCADE, o padrão para o comportamento é NO ACTION. Veja a tabela abaixo para mais detalhes:
| Opção | Comportamento para o comando UPDATE | Comportamento para o comando DELETE |
| NO ACTION (default) | Não ocorre propagação. Um erro é retornado e um ROLLBACK é disparado. Por exemplo, se tentarmos deletar um cliente que possua pedidos então a exclusão falhará. Neste caso, será necessário primeiro excluir os pedidos para então excluir o cliente. | |
| CASCADE | Propaga o valor modificado nas colunas das tabelas que fazem referência (FK’s) | Deleta as linhas nas tabelas que fazem referência (FK’s) |
| SET NULL | Seta NULL nas colunas das tabelas que fazem referência (FK’s) | |
| SET DEFAULT | Seta para o valor default nas colunas das tabelas que fazem referência (FK’s) | |
Particularmente acho a opção CASCADE bastante perigosa. Por isso, recomendo cautela ao utilizá-la.
-- Dropa as tabelas de CLIENTES e PEDIDOS para recriá-las DROP TABLE dbo.Pedidos; DROP TABLE dbo.Clientes; go CREATE TABLE dbo.Clientes ( Id int not null primary key, Nome varchar(50) not null ); INSERT dbo.Clientes VALUES (1, 'José'), (2,'Maria'); CREATE TABLE dbo.Pedidos ( Id int not null primary key, Cliente_Id INT NOT NULL, Data datetime2 not null, Valor decimal(15,2) not null, CONSTRAINT FK_Pedidos_x_Cliente FOREIGN KEY (Cliente_Id) REFERENCES dbo.Clientes(Id) ON DELETE CASCADE ON UPDATE CASCADE ); Declare @Cliente_Id INT = 1; INSERT dbo.Pedidos (Id, Cliente_Id, Data, Valor) VALUES (1, @Cliente_Id, GETDATE(), 122.45);
Até aqui recriamos as tabelas usando uma foreign key com a opção cascade para as operações de DELETE e também de UPDATE. Agora, vamos excluir o cliente de ID = 1 e verificar o que acontece.
delete dbo.Clientes where Id = 1; select * from dbo.Pedidos;
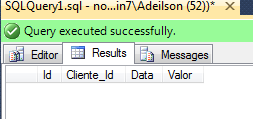
Veja que a exclusão foi propagada e os pedidos do Cliente de ID = 1 também foram excluídos.
![[SQL Server] Exame 70-461 – Tópico 3: Projetando Views – Parte 1](https://certificacaobd.com.br/wp-content/themes/Extra/images/post-format-thumb-text.svg)
Fala Adeilson!
Pessoal dica:
Caso utilize ON DELETE SET DEFAULT ou ON UPDATE SET DEFAULT
lembre-se que o valor default tem que estar contido na tabela que possui a chave primária,
caso não esteja o SQL Server irá disparar um erro de quebra de integridade.
Obrigado pelo artigo! Menos um tópico!
Muito obrigado por esse artigo.
Vc pretende fazer mais ?