

Introdução
Clientes Oracle cloud services enfrentavam a um longo tempo um problema referente utilização de memória estar sempre a um nível maior que 90% de consumo. Em muitos momentos parecia algo incomum e não realista, realizado uma pesquisa sobre esse caso foi descoberto um “bug” no processo de extração das informações referente a memória no Linux (da perspectiva Oracle), que foi responsável pela geração deste número não condizente com a realidade.
Declaração do problema
Oracle Enterprise Manager (OEM Grid Control) faz uso do utilitário sysstat, que são coleções de ferramentas de monitoração de performance para Linux, o SAR é a ferramenta utiliza para extração de informações sobre utilização de memória, essa utilização de extração foi induzido a um erro que refletiu em métricas do OEM Grid Control (mostrando números que não refletem a realidade dos fatos). Não foi validado se houve essa correção no OEM Cloud Control 12c.
Demostraremos abaixo o motivo dessas métricas enganosas.
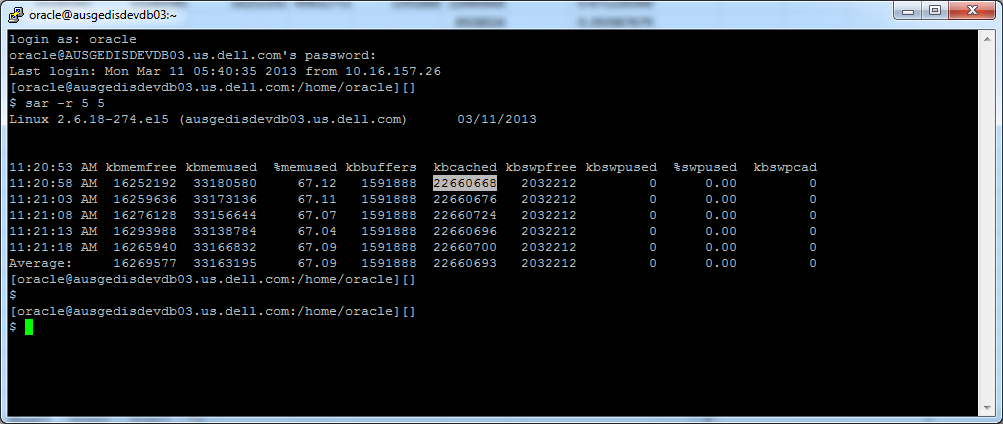
OBS.: Para extrair é usado o comando “sar” em combinação ao parâmetro “r”, que corresponde a utilização de memória, o comando completo é “sar -r 5 5”.
O campo “%memused” que representa a porcentagem de uso de memória, o cálculo para obter essa métrica referente a utilização de memória, se dá pela seguinte formula:
%memused = (kbmemused/(kbmemused+kbmemfree)) * 100
O intuito do sistema operacional Linux é fazer uso do recurso de memória principal da melhor forma possível, assim é considerado como recurso desperdiçado área de memória livre, uma vez que esse espaço pode ser usado para buffers e cache, promovendo um ganho em operações de I/O.
- Buffers = Quantidade de memória física usada como buffers em operações de escrita para disco. (Escrita: Entrada de dados de memória para disco)
- Cache = Quantidade de memória física usada como cache em operações de leitura em disco. (Leitura:Saída de dados de disco para memoria)
Para obter a porcentagem efetivo de uso de memória, devemos excluir os buffers e cache, contabilizando assim somente o uso liquido da memória RAM.
Utilização de Memoria = ((kbmemused-kbbuffers-kbcached)/(kbmemused+kbmemfree)) * 100
A seguir é descrito um exemplo com o cálculo da utilização de memória, sob duas perspectivas são elas:
- Utilização de Memoria Bruta
Este é o cálculo que o utilitáriosar faz na extração do campo “%memused”, ou seja, o sistema operacional Linux considera Cache e Buffer na contabilização da porcentagem de uso da memória.
Exemplo :
| Kbmemused | kbmemfree | kbbuffers | kbcached |
| 33180580 | 16252192 | 1591888 | 22660668 |
- Utilização de Memoria Liquida
Este é o cálculo real referente a memória usada, ou seja, este percentual referente a quantidade total da memória que efetivamente está sendo usada, desprezando cache e buffer.
Se utilizarmos o utilitário top para verificar a utilização da memória, a situação em primeiro momento parece terrível, dando a falsa impressão que toda a memória está sendo usada. Veja no exemplo abaixo.
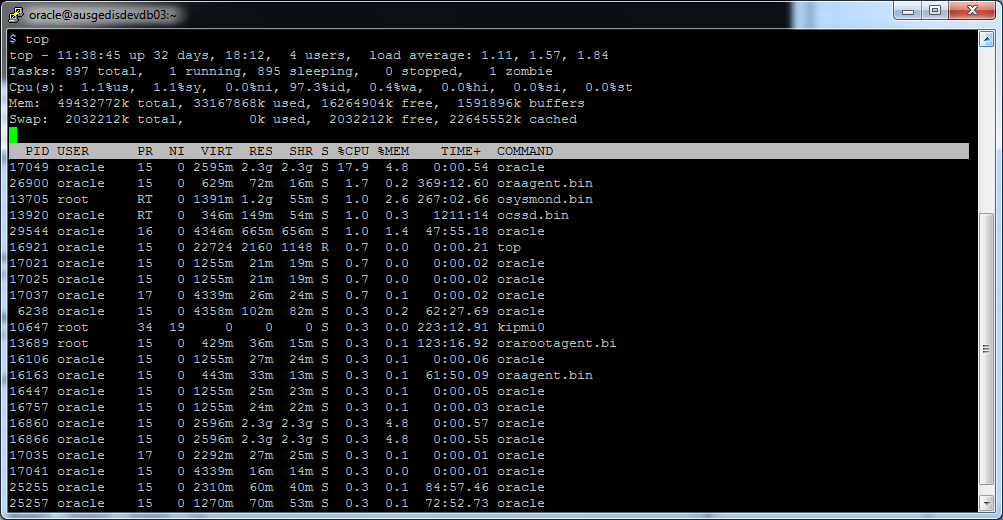
O utilitário top traz as seguintes informações:
| KB | MB | GB | |
| Total de Memória Física | 49432772 | 48274.19141 | 47.14277 |
| Memória Usada | 33167868 | 32390.49609 | 31.63134 |
| Memória Livre | 16264904 | 15883.69531 | 15.51142 |
O cache é uma dimensão parcial localizada na memória principal (Memória RAM), em operações de leitura em disco, os blocos oriundos da leitura é armazenado temporariamente no cache, caso haja uma nova necessidade de usa-las, assim tornando a operação de leitura mais performática. A área temporária de cache é dinâmica, ou seja, frequentemente é necessário ceder espaço caso algum processo requeira mais recurso em memória.
Com o objetivo de ter uma melhor visibilidade de utilização de memória, usaremos o comando free.

A linha que corresponde a “Mem:”, informa que o sistema computacional tem 48274 MB de memória (47,14GB), dos quais 32581 MB (31,81GB) está sendo usado e 15693MB (15,32GB) está livre. A coluna de memória “shared” é obsoleta e deve ser ignorada. A coluna buffers mostra que 1554MB (1,51GB) está sendo usada como buffers para em operações de escrita para disco, já a coluna cached mostra que 22106MB (21,58GB) está sendo usada como cache de operações de leitura em disco. É importante ressaltar que áreas de buffers e cache, assim como as áreas livres (free) estão disponíveis para uso. Na linha que corresponde a “-/+ buffers/cache:” mostra de maneira mais clara o uso real de memória, onde no campo free termos o valor de 39354MB (38,43GB), esse valor representa a quantidade de memória livre para uso, ou seja, é a soma da quantidade de buffers, cache e free (15693MB + 1554MB + 22106 MB). Assim, é importante notar que, deveríamos nos concentrar na segunda linha “-/ + buffers/cache:” para obter informações sobre memória disponível no sistema.
![[VirtualBox] Configurar pastas compartilhadas](https://certificacaobd.com.br/wp-content/uploads/2012/05/virtualbox.png)
![[Linux] Instalação (parte 1): OEL Oracle Enterprise Linux 6.2 sob VirtualBox](https://certificacaobd.com.br/wp-content/uploads/2012/05/virtualbox_dest1.png)
![[Oracle] How to Install Oracle 11g on Linux with ASM](https://certificacaobd.com.br/wp-content/themes/Extra/images/post-format-thumb-text.svg)
![[Oracle] Instalação (parte 2): Oracle Database 11.2 sob Oracle Linux 6.2 com VirtualBox](https://certificacaobd.com.br/wp-content/uploads/2012/03/oracle_dest.jpg)
{kind=link}
Carlos, parabéns pelo artigo. Você por acaso já experimentou casos em que o servidor chega a fazer paginação (coluna pi > 0 no resultado de vmstat) embora haja bastante memória livre (considerando os buffers/cache) ? Nestes casos eu uso um programa em C que encontrei no site da Oracle, que simplesmente faz alocação de memória (ex: fazer alocação de 6G de memória e depois liberar) para poder forçar a liberação de um pouco de memória que está no cache/buffer. Sei que isto parece meio extremo, mas pelo menos me deixa mais tranquilo. Entre o sistema não paginar e ter bastante memória pronta para operações de leitura/escrita eu prefiro que ele não faça paginação. O que você acha?
High Memory Utilization on Linux Systems (Doc ID 304215.1)
Felipe,
Acho valido sim essa ação, inclusive já implementei em alguns server database, porem somente naqueles servidores mais antigos com oracle 9 ou 10 (veja que a nota é para Linux Kernel – Version: 2.4.9 to 2.6.9), no caso daqueles mais recentes não cheguei a implementar, ao invés disso passei a usar o mecanismo de hugepages, que melhorou bastante nos Kernel mais recentes. O uso de SWAP somente é “ruim” quando efetivamente a máquina está com déficit de memória, ou seja, o linux deixa de usando memória para se beneficiar com cache e passa a usar por necessidade, isso é ruim, por ironia, é muito parecido visualmente o uso bom (…usando memória para se beneficiar com cache…) e o uso ruim (…passa a usar por necessidade…), por isso é legal a necessidade de uma análise mais profunda.
Olhando somente para o banco de dados, caso não seja possível uma leitura de blocos oriundos da SGA, eu prefiro que essa leitura se estenda para o disco ao invés de ir para o cache do linux, essa abordagem é comum no ASM e em alguns outros sistemas de arquivos com o nome de “Direct IO” (Em muitos casos não acho vantajoso usar cache, caso olharmos para a perspectiva de performance).
Voltando ao assunto de SWAP , CACHE e BUFFER, também é valido, estudar uma mudança da configuração para padrão do seu SO, como por exemplo, aumentar o fluxo de gravação de “páginas sujas” do linux, diminuindo assim a intensidade de buffers, pesquise pelos parâmetros abaixo:
vm.dirty_background_ratio
vm.dirty_ratio
vm.dirty_expire_centisecs
vm.dirty_writeback_centisecs
E também a tendência de intensidade e agressividade de executar swap, controlada pelo parâmetros vm.swappiness.